Using custom functions in Power Query (to boost performance)
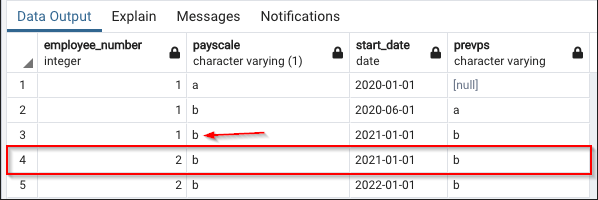
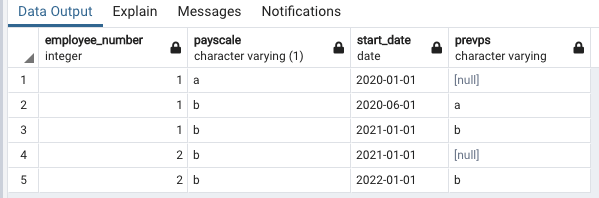
In this blogpost we have seen how to import multiple Excel files from a folder. During this process, we have imported all sales data from the various sales representatives and afterwards expanded all of the nested tables, which in return combined all of the data. In this particular example, the combined Excel files resulted in 150.000 rows total, which is still easily handled by Power Query. But let’s imagine an example in which we import 10 files with 100.000 rows each. After combining the Excel files, the total amount of rows will be 1 million. If all data is relevant, this should not be an issue. But what if we only need the data for one of the many sales representatives, which is only 25.000 rows total? If we combine all of the data, Power Query will expand the nested tables to 1 million rows and we can filter on the relevant sales representative afterwards, but the fact that we are expanding all 1 million rows will have a negative impact on the performance. What if there was a way to filter all of the nested tables before expanding the data? That’s were a custom function can come in handy. In order to understand how to write a custom function, we first need some basic knowledge of the M-code that Power Query generates when applying query steps.
The Power Query M-language
When using the user interface, Power Query will generate multiple query steps for you:
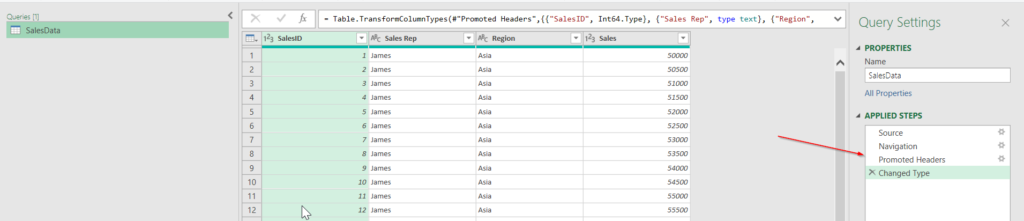
In the screenshot above we have applied the following steps:
- Source: import Excel file
- Navigation: navigate to relevant object in the Excel file
- Promoted Headers: used the first row as headers
- Changed Type: changed the datatype of all of the columns
All of those steps that we apply via the user interface, generate M-code on the background. If we now click on the advanced editor, we can see the M-code that was generated:
In the advanced editor we can see the following code:

In the code above, we can find our query steps. The way Power Query works, is that it first defines all of the expression steps (query steps) after the “let” expression. After the “let” expression, all expression steps are composed and form the mashup query. in the final step, the last expression step is outputted after the “in” expression. Each of the expression steps start with the query step name, for example #”Changed Type” after which the relevant M-code is written. In the example above, each step starts with a function, such as “Table.TransformColumnTypes”. The first parameter of a function is always the name of the previous step. If we look at the #”Changed Type” step, the Table.TransformColumnTypes function takes the “Promoted Headers” step as the first parameter, which is the previous query step. This little piece of basic information will help us understand how to build our custom function. A future blogpost will be dedicated to the Power Query M-language and the way the engine works.
Building the custom function
In the earlier blogpost, we expanded all the data and then applied our data manipulation steps afterwards. This means that when looking at the situation in the screenshot below, we would expand all the data that is stored in the nested tables in the 2nd column:
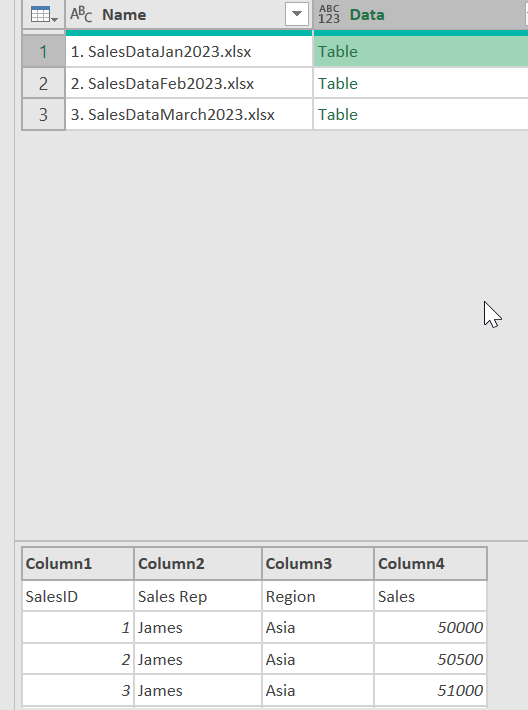
If we need all the data, that is perfectly fine. But let’s imagine that we only need the data for the sales representative James. In this case it would be efficient to filter the nested tables to only contain data for sales representative James and expanding the nested tables afterwards. Nested tables can be manipulated just like a regular table (as we are doing when using the User Interface), but we need to apply all of the query steps in the nested table itself. Now we first need to determine what data manipulation steps we want to apply to the nested tables. For this we import one single sales file to Power Query (it does not matter which file, any of the files in the folder is fine):
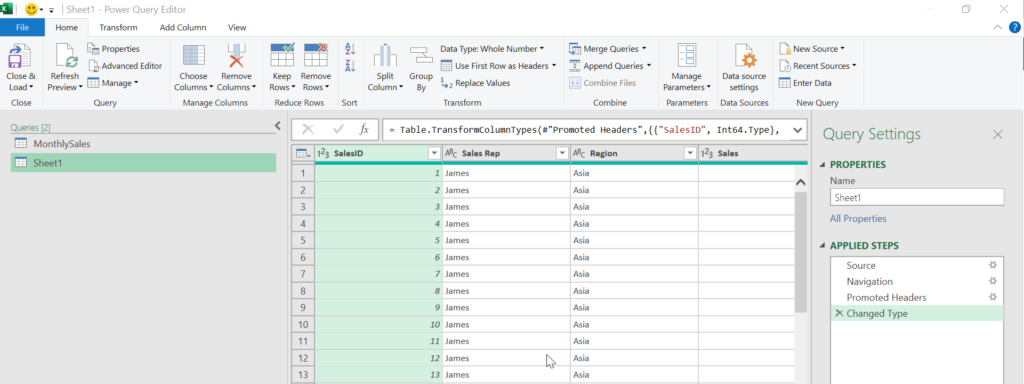
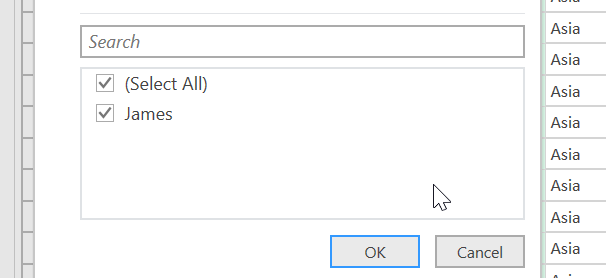
We are not going to actually use this query, we are just getting the relevant code from it. The “Promoted Headers” and the “Changed Type” steps are automatically generated by Power Query. The next thing we want to do, is filter the data to only include data for James:

After applying this filter, a new “Filtered Rows” step is added:
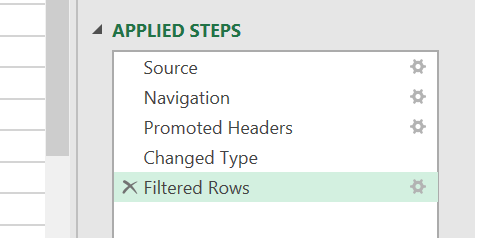
The steps that we now have applied, are the steps that we want to apply to all the nested tables:
- First we want to promote the headers
- Then we want to change the datatype of the columns
- Finally we want to filter the table to only contain data for James
Let’s have a quick look at the M-code that has been generated via the three query steps:
#"Promoted Headers" = Table.PromoteHeaders(Sheet1_Sheet, [PromoteAllScalars=true]),
#"Changed Type" = Table.TransformColumnTypes(#"Promoted Headers",{{"SalesID", Int64.Type}, {"Sales Rep", type text}, {"Region", type text}, {"Sales", Int64.Type}}),
#"Filtered Rows" = Table.SelectRows(#"Changed Type", each ([Sales Rep] = "James"))We can find the all of the three steps in the code above. Those three query steps is what we want to apply to our nested tables. If we go back to the advanced editor to see the full M-code, we can find additional query steps:

The source step and the navigation step (the first 2 steps) are not relevant for us. This because we already have defined the source and the navigation steps in our main query, which resulted in the nested tables. We are only interested in the “Promoted Headers”, “Changed Type”, and “Filtered Rows” steps. We will remove the first two steps:

The next step is to transform the M-code above into a custom function. We can use the following operator to start a custom function:
=>Before the custom function operator, we have to specify our input parameters and afterwards the relevant M-code will follow. Let’s start our custom function:

In the example above, our input parameter is called “TableToTransform” which is followed by the relevant M-code containing the query steps that we want to apply. Since each applied query step will always start with a reference to the previous query step, the code above is not yet complete.

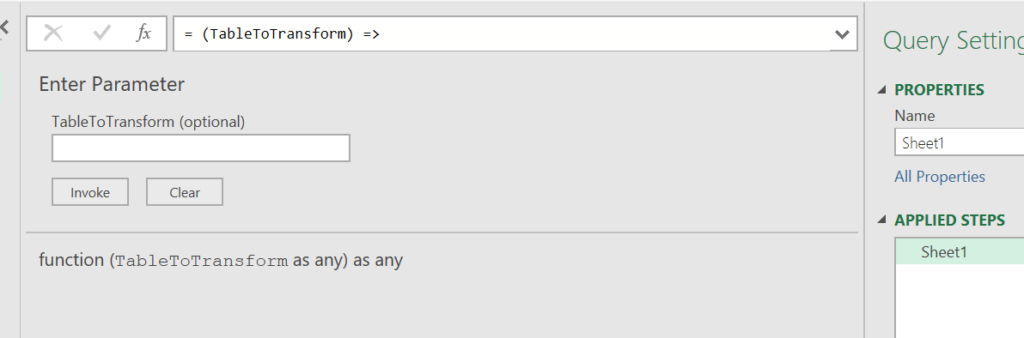
The first query step still refers to the previous step in the old situation. We have stripped this M-code down, so this will not work. The first query step has to be applied to our nested table. In the custom function we are passing the nested tables as input parameters, and since we have created our TableToTransform input parameter, we can use this in the first query step:

If we click done, our custom function has been built:
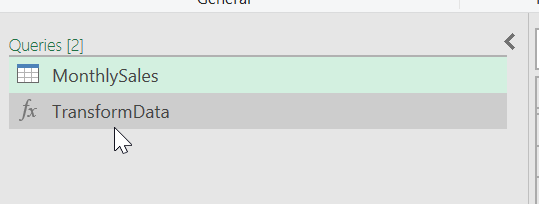
In our Queries overview, we can now also find the custom function, which has been renamed to TransformData:
When we will use the custom function, it will do the following:
- It will take the nested table as the input
- In the nested table, the first rows will be promoted as headers
- In the nested table, the datatypes will be changed
- In the nested table, a filter will be applied to only include sales data for James
Now let’s use our created custom function. For this we go back to our query with the nested tables and click on “Invoke Custom Function”:
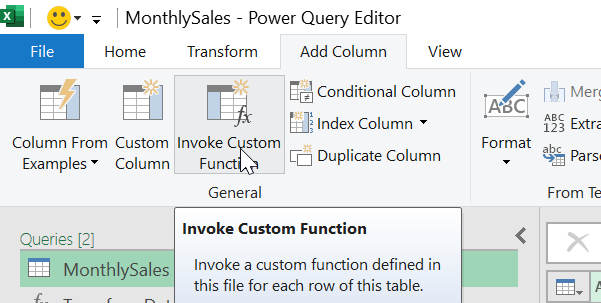
The following windows pops up:
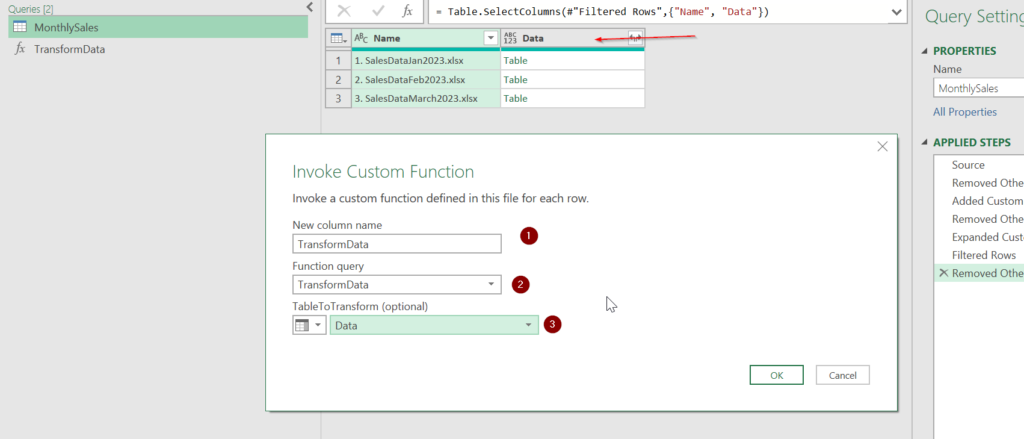
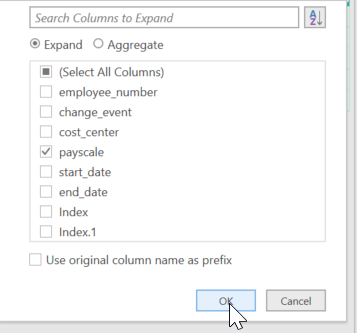
In the first window, we specify the new column name. In the second window we choose the function the we want to use, TransformData in this case (we only have one available function). In the third window we have to specify which column we want to use the function on. Since the “Data” column holds all of our nested tables, we choose this column. After clicking on “OK” the function is applied and a new column appears:

This new column again, holds nested tables, but those tables contain data that has been manipulated based on our function:
- The first row is promoted to headers
- The datatypes are changed
- The table only contains data for James
Now let’s remove the column with the old nested tables:

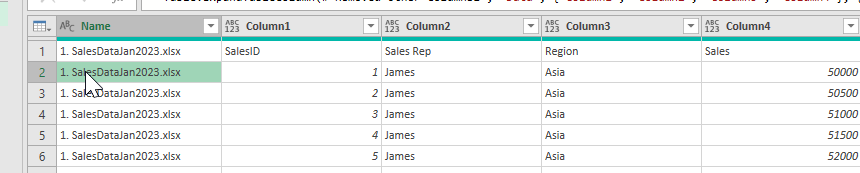
After expanding our new nested tables, only data for James is expanded:
In this rather simple example, we can see the power of a custom function. Custom functions can be used in a wide range of situations to increase efficiency but also to help with complex transformations. In a future blogpost I will demonstrate how a custom function can be used to tackle a complex transformation challenge. Only when you are aware of the power of custom functions, you will start to see use cases during your own work…